 science-review.ru
science-review.ru
Scientific journal
Scientific Review. Physics and Mathematics
CLASSIFICATION OF OBJECTS BY PROCESSING A SMALL SAMPLE OF DATA BY A CONVOLUTION NEURAL NETWORK

Введение. Одной из проблем, требующих решения с помощью современных методов обработки данных, является задача машинной классификации объектов (то есть сортировки выборки объектов по классам) [1].
Классификация данных используется во многих отраслях, например, таких как:
- защита информации, где необходимо отделить секретную и важную информацию от менее важной, актуальные данные от неактуальных;
- отделение исправных изделий от неисправных;
- создание контекстных выборок в веб-приложениях [2];
- медицинская диагностика;
- распознавание образов на изображениях.
В настоящее время наиболее эффективным инструментом для создания классификаторов является использование программ, в основе которых лежат методы искусственного интеллекта (чаще всего, основанные на применении нейронных сетей).
В представленной работе рассмотрена реализация двухклассового распределения изображений с помощью функций библиотек обработки данных и нейросетевого программирования Keras, SkiPy, PIL.
Особенность представленной задачи заключается в том, что нейросеть должна иметь специальную архитектуру для работы с относительно небольшим количеством не очень качественных исходных данных для обучения и валидации – топографию с использованием свёрточных слоёв [3]. Данное направление развития нейросетей в настоящее время является очень востребованным, т.к. обычно сложно получить базу данных по объектам с большим количеством качественных данных.
Цель исследования. Частной задачей данного исследования является создание нейронной сети для классификации изображений – разбиения базы фотографий на два класса – изображений кошек и собак (бинарная классификация). Для обучения и валидации создаваемой сети используется относительно небольшая база фотографий в формате .jpg. При этом выбираются первые попавшиеся по поиску в системе google, как правило не очень качественные, фотографии кошек и собак, на многих из которых присутствуют также люди и множество посторонних предметов, а изображения животных занимают часто только малую площадь изображения.
Для обучения сети используется по 1000 произвольно выбранных фотографий по каждому классу (всего 2000 изображений), для валидации – по 400 фотографий по каждому классу.
При этом используются специальные возможности модуля Keras [4]:
- функция создания генератора для обучения модели Keras;
- специальное сочетание разных типов слоёв нейросети для эффективной работы с небольшим массивом данных;
- тонкая настройка модели с помощью длительного обучения.
При использовании больших выборок данных и методик глубокого обучения можно достичь точности классификации до 98%. Однако, при работе с малой выборкой некачественных данных достижимая точность классификации гораздо ниже. Более ранние исследования, проведённые с базой данных из 25000 изображений, показали, что при классификации можно добиться точности не более 60% [5]. Однако, в последнее время после детальной разработки архитектуры нейросети, работающей с малой выборкой данных, наблюдается значительный прогресс и в некоторых случаях достигнута точность классификации до 80%.
Данное исследование посвящено именно проблеме использования малых выборок. В данном случае для целей классификации лучше всего зарекомендовали себя достаточно сложные свёрточные (convolution) нейросети с использованием метода глубокого обучения, которые и применены в разрабатываемой программе.
Разработанный подход был опробован на специально созданной нейросети, на основе которой скомпилирована и обучена модель классификации. Следующей задачей, решаемой в работе, является оценка достигаемого качества классификации объектов.
Материал и методы исследования. Рассмотрим кратко принципы, использованные в процессе создания программы на языке Python для классификации объектов с помощью нейронной сети специальной архитектуры с применением функций библиотеки Keras.
Как уже отмечено выше, наиболее подходящим инструментом для осуществления классификации изображений является применение свёрточных сетей. Основным их свойством является способность выделять характерные особенности исследуемых объектов и поэтому в сфере распознавания образов у них на данный момент нет конкурентов.
Принцип организации свёрточной сети основан на том, что пиксели изображения, находящиеся рядом, более сильно влияют на характеристику моделируемого признака, чем пиксели, находящиеся далеко друг от друга [6].
Свёрточная сеть является намного более «продвинутым» вариантом обычной, полносвязной, нейронной сети, в котором для дополнительной обработки областей изображения применяется так называемая свёртка. В библиотеке Keras свёрточный слой общей нейросети обозначается Conv2D. Этот слой подобен полносвязному слою, и так же содержит веса и смещения, которые подвергаются оптимизации (подбору). Кроме того, слой Conv2D содержит ещё фильтры («ядра»), создающие свёртки, значения параметров которых также должны оптимизироваться.
В нашей задаче использовано мало обучающих образцов, поэтому главная задача – не дать сети переобучиться [7]. Переобучение происходит, когда модель начинает действовать по неправильным шаблонам, обобщая и выводя правила из абсолютно частных образцов данных (подобно образованному человеку, не умеющему применять свои многочисленные знания на практике).
Основным направлением борьбы с переобучением является подбор энтропической мощности (entropic capacity) модели – то есть насколько много информации разрешено хранить внутри модели. Модель, которая может хранить много информации, может быть более точной за счёт использования большего количества функций, но она также в большей степени подвержена риску хранения неверных функций. Между тем, модель, которая может хранить только несколько функций, должна будет сосредоточиться на наиболее значимых особенностях, найденных в данных, и они, скорее всего, будут действительно верны и будут обобщены лучше.
Существуют различные способы подбора энтропической мощности. Основной из них - выбор количества параметров в модели, т.е. количества слоев и количество нейронов каждого слоя. Второй способ – подбор модели оптимизации энтропии при компиляции созданной нейросети.
В нашем случае используется свёрточная сеть с большим количеством слоев и с применением фильтров на каждом уровне обработки данных, применяемых для отсева данных. Отсев лишних данных способствует снижению опасности переобучения, не позволяя слою обрабатывать дважды одинаковую картину, таким образом устраняя ложное впечатление увеличения количества данных.
Разработанная нейронная сеть формируется последовательным соединением следующих слоёв [8] (рис. 1):
- InputLayer – входной слой для подачи на него обучающих образцов изображений;
- Три последовательных свёрточных слоя Conv2D, связанных с активационными слоями Activation с передаточной функцией ReLU (линейный выпрямитель Rectified Linear Unit) и последующими выходными тензорами MaxPooling2D. Целью активационного слоя является достижение бинарности данных на выходе («да-нет»), а выходные тензорные слои уменьшают размерность выходной выборки на основе выбора только максимального значения из подвыборок размером pool_size;
- Flatten - слой для преобразования изображения выходной выборки в одномерный вектор;
- Два полносвязных слоя Dense с последующей активацией слоями Activation, использующих соответственно функцию ReLU и сигмоидную функцию. Между данными слоями внедрён дополнительный слой Dropout - слой прореживания для решения проблемы переобучения сети.
Выход сети является бинарным с двумя вариантами классификации (кошка-собака).
После задания типов и параметров слоёв в программе предусмотрены команды для вывода топографии нейросети на экран и в графический файл (рис. 1).
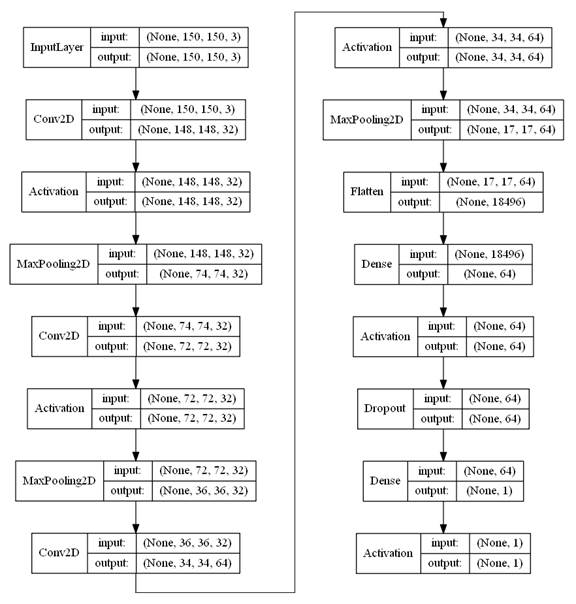
Рис. 1. Топография созданной нейронной сети.
Затем производится компиляция созданной нейросети, для чего использован метод бинарной кроссэнтропии в качестве функции потерь (её назначение описано выше), метрика точности и один из самых современных оптимизаторов адаптивного обучения Rmsprop [9].
После этого осуществляется собственно процесс обучения сети и создания модели классификации. Для исключения переобучения применяется функция перемешивания обучающей выборки и генерации некоторого дополнительного объёма данных с помощью класса предобработки изображений ImageDataGenerator модуля Keras. Этот класс позволяет, в частности, поворачивать изображения на произвольный угол, перемещать их по вертикали или горизонтали, масштабировать и изменять палитру цветов изображения.
После каждого цикла (эпохи) обучения производится валидация модели на соответствующем наборе изображений и определяется точность осуществления ею классификации. Значения достигнутой точности записываются в массив данных.
В начале программы в качестве исходных данных заданы переменные с параметрами выборки данных и настройками обучения сети. Например, в рассматриваемом случае задаётся размер изображений (150×150 пикселей), пути к директориям на жёстком диске, в которых размещены обучающие и валидационные выборки изображений, количество образцов изображений для обучения сети и её валидации, число эпох обучения.
Также задаётся размер подвыборки из 16 изображений. Такое деление изображений на подвыборки необходимо для ускорения работы компьютера и исключения переполнения оперативной памяти.
В конце программы заданы команды для вывода на экран и в файл графика по результатам обучения модели, а также для сохранения самой модели в файл для возможности её дальнейшего использования для целей классификации объектов (для этого написана отдельная небольшая программа на языке Python).
Результаты. Выполнение расчётов с помощью созданной программы осуществлялось на компьютере с двухъядерным процессором (CPU) с тактовой частотой 2 ГГц и 4 Гб оперативной памяти. Обучение модели по 100 эпохам заняло около 15 часов. Это время может быть значительно сокращено при использовании более мощной конфигурации компьютера и процессора мощной графической карты (GPU вместо CPU).
Созданный массив результатов оценки точности классификации в процентах в зависимости от количества эпох обучения выведен в графическом виде с помощью библиотеки Matplotlib на рис. 2.
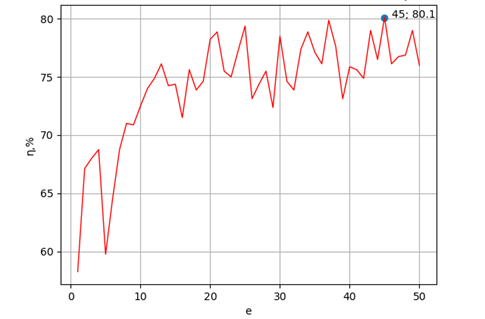
Рис. 2. Зависимость качества классификации нейросетью от количества эпох обучения.
По графику видно, что качество обучения колеблется в зависимости от количества эпох и вначале качество классификации в среднем увеличивается. Колебания оценки качества модели можно объяснить наличием неявной связи между архитектурой сети и числом эпох. Наилучшее качество обучения (более 80%) было достигнуто при числе эпох 45. При дальнейшем увеличении количества эпох качество модели не повышается (график изображён только для 50 начальных эпох, т.к. далее оценка качества колеблется около значений 75-80%, не превышая их). Полученное качество обучения близко к предельно допустимым значениям при небольшом наборе данных, поэтому можно сделать вывод, что использованная топография сети с применением свёрточных слоёв хорошо справилась с задачей бинарной классификации.
Обсуждение и заключение. Особенность модели, основанной на описанной нейросети, имеющей в составе несколько свёрточных слоёв, состоит в том, что она способна реализовать высокое качество классификации объектов даже при малом количестве исходных данных для обучения и валидации. Такой анализ данных является крайне востребованным в настоящее время, так как абсолютное большинство баз данных как раз состоят из небольшого объёма не очень качественных образцов данных.
По результатам выполненной работе можно сформулировать следующие рекомендации:
- при разбиении исходной базы данных следует отводить на обучающую выборку в несколько раз большее количество объектов, чем на валидационную выборку;
- важно правильно подобрать топографию нейронной свёрточной сети, которая будет давать высокое качество классификации именно при малом количестве исходных данных;
- надо использовать наиболее современный и совершенный метод компиляции сети;
- избегать переобучения сети, которое в рассматриваемой задаче очень вероятно;
- при разработке модели можно использовать оценку её качества, предложенную в статье.
Описанные принципы создания и обучения свёрточных нейросетей с использованием модуля Keras [10] и прочих библиотек языка Python рекомендуется применять также для классификации любых других объектов по малым выборкам данных.
Библиографическая ссылка
Ильичев В.Ю. КЛАССИФИКАЦИЯ ОБЪЕКТОВ ПРИ ПОМОЩИ ОБРАБОТКИ МАЛОЙ ВЫБОРКИ ДАННЫХ СВЁРТОЧНОЙ НЕЙРОСЕТЬЮ // Научное обозрение. Физико-математические науки . 2020. № 1. С. 3-3;URL: https://physics-mathematics.ru/en/article/view?id=91 (дата обращения: 24.06.2026).